![]()
Regular Expressions (Regex) are used to identify strings that defy simple search terms, which infosec and technology professionals use for things like input validation, searching and scripting. Unfortunately, the syntax can be intimidating and the learning curve steep for beginners. Throw in a handful of different flavors and the confusion grows. While it can be a lot of information upfront, once you’ve spent some time on it, the syntax becomes natural and you may even start wishing all search bars allowed regex! This article offers a short guide for anyone interested in learning the syntax or adding a few new tools to their regex belt.
Where can I use Regex?
- Command line/grep
- Scripting
- Burp
- Text editors designed to handle code
- Notepad++, Sublime, etc.
- Input validation
How?
- Practice
- Really practice
- Attempt things multiple times
- Come up with ways to work it into your routine
- Time to practice
- It’s really just practice
- Create code which uses regex
- Enter into a world of wonder and practice
A note about exercises:
The exercises included in this guide use publicly available web pages which are subject to change and may cause a different result from the example presented here. There are also many different right answers to most regex problems; the ones provided here correspond to the material covered in a given section to illustrate how a regex could be formed using the techniques presented.
A Quick Pit Stop to Refresh Our Shortcut Knowledge
1 – The Basics of Find and hReplace:
- Almost everything, such as browsers, Excel, and notes, uses this keyboard shortcut that opens a search box to find the text: CTRL-F
- Bonus: double-click
- Sometimes you can double click on a word or chunk of text and it will highlight all instances thereof and/or auto-populate the ‘find’ field if followed by a find or find and replace shortcut. Example from Notepad++:
- Bonus: double-click
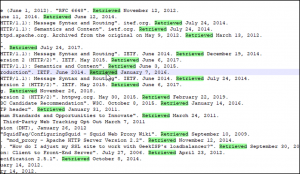
-
- Find and Replace: CTRL-H
- This works on most editors, including Word.
- Find and Replace: CTRL-H
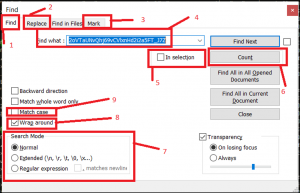
Notepad++ Options
- CTRL-F
- CTRL-H
- Permanently highlight all instances of the item in the find field.
- Find field
- If you highlight a chunk of text followed by CTRL-F/H, you can then search within only that chunk as opposed to the whole file.
- Count how many instances there are of the given search term
- Different modes for different search types
- Normal – just like your standard browser or Word editor; it searches for the exact string you provided.
- Extended – standard + you can use certain special characters such as newline, carriage return, tab, etc.
- Regular expression – regex
- ‘.’ matches newline – use with caution.
Try it at Home – Regexercise 1: Simple Searching
Find all instances of the word “user” on this page: https://www.criticalstart.com/cisco-umbrella-enterprise-roaming-client-and-enterprise-roaming-module-privilege-escalation-vulnerability/
Note the differences between instances. How would you look for only “user” and not “users”? What if you wanted only the cases where it’s the last word in a sentence? We’ll look at problems like this throughout this post.
Back to Regex
2 – Dates: Letters, Numbers, Groups, Logical OR and NOT, Character Sets, and Quantifiers
2.1, 2.2 – Letters and Numbers
\w – “word” characters (letters), e.g. a-z and A-Z. \w represents one single character.
\d – “digit” characters (numbers), e.g. 0-9. \d is a single character and not understood as an actual number. For example, 3 can be represented by \d, but 10 cannot; instead, 10 would be represented as \d\d.
Try it at Home – Regexercise 2.1: Find all dates of a given format
- Copy the text from this Wikipedia article into a text editor which allows regex searching.
- For best results, copy starting from the text “List of HTTP header fields” and ending at the text “Internet-related lists”.
- Link: https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
- Find every instance of a date in this format: Tue, 02 Apr 2019 10:04:53 GMT
Try it at Home – Regexercise 2.2: Find all Expires headers
- Example
- Expires: Tue, 02 Apr 2019 10:04:53 GMT
- Count and compare to total number of dates
2.3 – Groups and ‘OR’
Groups “()” retain order and precise subsections, as opposed to sets.
| = ‘OR’ = logical XOR
- Example of a normal group which will look for either “normal group” or “regular group”:
- (normal|regular) group
- Groups are ‘capturing’ by default, e.g. the text in the parentheses is intended to be part of the final string, while a non-capturing group (shown below) is excluded from the final string.
- (?:non-capturing group)
- Example:
- Input Strings:
- “The final result will contain the 1st group, but not the second.”
- “The final result will contain the first group, but not the second.”
- “The final result will contain the 1st group, but not the 2nd.”
- “The final result will contain the first group, but not the 2nd.”
- “The final result will contain the 1st group, but not the 3rd.”
- “The final result will contain the first group, but not the third.”
- Your Regex:
- “The final result will contain the (first|1st) group, but not the (?:second|2nd).”
- Valid Results:
- “The final result will contain the first group, but not the .”
- “The final result will contain the 1st group, but not the .”
- None of the sentences with 3rd or third in them are valid because 2nd or second must be present.
- Input Strings:
Try it at Home – Regexercise 2.3: Find all types of date headers except Expires
Example format:
- Name-of-Header: Tue, 02 Apr 2019 10:04:53 GMT
2.4 – Character Sets, “NOT”, and Quantifiers
- Character set [] examples:
- [A-Z] – any uppercase character in the alphabet
- [a-z] – any lowercase character in the alphabet
- [0-9] – any single digit
- [0-6] – any single digit between and including 0 and 6
- [\w\d] – any single character that is a letter or a number (no whitespace or special characters)
- Equivalent to (\w|\d)
- ^ – NOT
- [^abc] – any character (including whitespace, special characters, and numbers) that is not a, b, or c.
- ^ is used for other commands too, use with caution.
- Quantifiers {} * + ?
- Quantifiers follow characters, character sets, and groups to define how many should exist.
- Example: \w{4} is exactly 4 letters
- {,100} – any number of characters from 0 through 100
- {1,} – any number of characters from 1 through infinity
- {4} – exactly 4 characters
- {2,6} – any number of characters from 2 through 6, e.g. a{2,6} would be aa, aaa, aaaa, aaaaa, aaaaaa
- * – any number of characters from 0 through infinity
- Equivalent to {0,}
- + – at least one character, but can be as many as infinity
- Equivalent to {1,}
- ? – has 2 uses: optional and lazy
- Optional? – the character preceding the ? either appears once or not at all.
- Equivalent to {0,1}
- Optional? matches both Optional and Optiona
- (lazy)+? – is the quantifier preceding the ? must choose the smallest number of instances possible.
- Example: (lazy){3,}? matches lazylazylazy, but not lazylazylazylazy
- Optional? – the character preceding the ? either appears once or not at all.
- Quantifiers follow characters, character sets, and groups to define how many should exist.
Try it at Home – Regexercise 2.4: Find all date headers of this format using quantifiers
Example format:
- Name-of-Header: Tue, 02 Apr 2019 10:04:53 GMT
3 – Special Characters, Escapes, Exclusions, and Lookarounds
3.1 – Special Characters and Escapes
- \W, \S, \D
- Not word (letter), not whitespace (space, tab, etc.), not digit (number)
- \s, \r, \n, \t, \0
- Whitespace, carriage return (Windows), newline (Windows, Nix), tab, null character
- +*?^$\.[]{}()|/
- Need to escape with \, e.g. \*
- There are more options for escaping/encoding, such as unicode
- Only use for more complicated tasks, such as scripting
Try it at Home – Regexercise 3.1: Find all full HTTPS URLs
- https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
- Navigate to this page
- Right-click > View page source (or CTRL-U)
- Copy and paste the entire contents of the view-source:… page into a text editor which allows regex use.
- Find all HTTPS (not HTTP) URLs and their contents, e.g. https://myurl.wikipedia.com/directory?param=value¶m2=value2#locallink
3.2 – Exclusions and Lookarounds
Get some stuff, but not other stuff
- def[^abc]ghi – “def” followed by any single character (including whitespace, special characters, and numbers) that is not a, b, or c followed by “ghi”.
- Match examples:
- Match – def ghi
- Match – def2ghi
- Non-match – defbghi
- ^ is used for other regexing too; use with caution and only inside square brackets unless you know what you’re doing.
- Match examples:
- def(abc)ghi – capture group (see above).
- Match and result examples:
- Match – defabcghi, Result – defabcghi
- Non-match – anything else
- Match and result examples:
- def(?:abc)ghi – non-capturing group (see above).
- Match and result examples:
- Match – defabcghi, Result – defghi
- Match and result examples:
Lookarounds are non-capturing by default, meaning the items in the group must exist, but they will not be returned in the result.
- def(?=abc) – positive lookahead: requires a string containing “def” followed by “abc”, but only “def” is returned as a result.
- def(?!abc) – negative lookahead: requires a string containing “def” followed by anything BUT “abc”, and only “def” is returned.
- Match and result examples:
- Match: defqrs, Result – def
- Non-match: defabc, Result – no result
- Match: def%^&*(, Result – def
- Match and result examples:
- (?<=abc)ghi – positive lookbehind: requires a string containing “ghi” preceded by “abc”, but only “ghi” is returned as a result.
- (?<!abc)ghi – negative lookbehind: requires a string containing “ghi” preceded by anything BUT “abc”, and only “ghi” is returned.
Note: There are different interpretations of regex out there, especially when you get into this more complicated territory, so if something’s not working, google it and check out the resources below.
Try it at Home – Regexercise 3.2: Find only the part of the URL that appears after the domain/IP.
Bonus problem – find this part of the URL for the following:
- HTTP URLs (with or without the prefix)
- HTTP OR HTTPS
- HTTP AND HTTPS
- URIs in HTML tags
4 – Grepping
4.1 – Grep and Count
- grep –G “myregex” myfile.txt
- grep – command in Linux to search for lines containing a given expression
- -G – flag saying you’re grepping. There are several other valid flags available as well.
- “myregex” – a regular expression surrounded by double quotes, e.g. “[\w\d]*\.”
- txt – the file through which you’re grepping
- grep –G “myregex” myfile.txt -c
- -c – count how many matches to myregex there are in myfile
Try it at Home – Regexercise 4.1: Find line given port
After performing a legal, safe scan on something you own, practice grepping only the lines which have a given port open. A common example is also provided below.
For the following example, collect all the lines with port 80 open. Bonus: collect all the lines with port 80 open and not port 8080.
Example Nmap greppable output:
Host: 10.10.10.3 () Status: Up Host: 10.10.10.3 () Ports: 80/open/tcp//http///, 443/open/tcp//https/// Ignored State: filtered (998) Host: 10.10.11.10 () Status: Up Host: 10.10.11.10 () Ports: 21/open/tcp//ftp///, 22/open/tcp//ssh///, 25/open/tcp//smtp///, 80/open/tcp//http///, 10/open/tcp//pop3///, 103/open/tcp//imap///, 443/open/tcp//https///, 465/open/tcp//smtps///, 522/open/tcp//submission///, 993/open/tcp//imaps///, 995/open/tcp//pop3s///, 3306/open/tcp//mysql///, 8080/open/tcp//http/// Host: 10.10.12.65 () Status: Up Host: 10.10.12.65 () Ports: 21/open/tcp//ftp///, 22/open/tcp//ssh///, 25/open/tcp//smtp///, 80/open/tcp//http///, 10/open/tcp//pop3///, 103/open/tcp//imap///, 443/open/tcp//https///, 465/open/tcp//smtps///, 522/open/tcp//submission///, 993/open/tcp//imaps///, 995/open/tcp//pop3s///, 3306/open/tcp//mysql/// Host: 10.10.14.46 () Status: Up Host: 10.10.14.46 () Ports: 80/open/tcp//http///, 443/open/tcp//https/// Host: 10.10.10.10 () Status: Up Host: 10.10.10.10 () Ports: 80/open/tcp//http///, 443/open/tcp//https/// Ignored State: filtered (998) Host: 10.10.17.127 () Status: Up Host: 10.10.17.127 () Ports: 21/open/tcp//ftp///, 25/open/tcp//smtp///, 80/open/tcp//http///, 10/open/tcp//pop3///, 103/open/tcp//imap///, 443/open/tcp//https///, 465/open/tcp//smtps///, 522/open/tcp//submission///, 993/open/tcp//imaps///, 995/open/tcp//pop3s///, 3306/open/tcp//mysql///, 1032/open/tcp//postgresql/// Host: 10.10.16.78 () Status: Up Host: 10.10.16.78 () Ports: 21/open/tcp//ftp///, 22/open/tcp//ssh///, 443/open/tcp//https///, 8443/open/tcp//http/// Host: 10.10.16.19 () Status: Up Host: 10.10.16.19 () Ports: 80/open/tcp//http///, 443/open/tcp//https///, 4103/open/tcp//unicall/// Host: 10.10.23.43 () Status: Up Host: 10.10.23.43 () Ports: 21/open/tcp//ftp///, 25/open/tcp//smtp///, 53/open/tcp//domain///, 80/open/tcp//http///, 10/open/tcp//pop3///, 103/open/tcp//imap///, 443/open/tcp//https///, 465/open/tcp//smtps///, 522/open/tcp//submission///, 993/open/tcp//imaps///, 995/open/tcp//pop3s/// Ignored State: filtered (989) Host: 10.10.25.10 () Status: Up Host: 10.10.25.10 () Ports: 21/open/tcp//ftp///, 22/open/tcp//ssh///, 25/open/tcp//smtp///, 80/open/tcp//http///, 10/open/tcp//pop3///, 103/open/tcp//imap///, 443/open/tcp//https///, 465/open/tcp//smtps///, 522/open/tcp//submission///, 993/open/tcp//imaps///, 995/open/tcp//pop3s///, 3306/open/tcp//mysql/// Host: 10.10.10.8 () Status: Up Host: 10.10.10.8 () Ports: 80/open/tcp//http///, 443/open/tcp//https/// Host: 10.10.24.35 () Status: Up Host: 10.10.24.35 () Ports: 80/open/tcp//http///, 443/open/tcp//https/// Host: 10.10.119.204 () Status: Up Host: 10.10.119.204 () Ports: 22/open/tcp//ssh///, 80/open/tcp//http///, 443/open/tcp//https/// Ignored State: filtered (997)
4.2 – Cut and Sort
- grep –G “myregex” myfile.txt | cut –d ‘:’ –f2 | sort –u
- | cut -d ‘:’ -f2
- send the output to the next command |, cut up each matched line using a colon as the -delimiter, and select only the 2nd -f
- | sort -u
- send the output to the next command |, sort the output alphabetically, then remove duplicates leaving a list of unique lines -u.
- | cut -d ‘:’ -f2
Try it at Home – Regexercise 4.2: Find a unique list of IPs with a given port open.
From your (safe, legal) greppable output or the example above, collect a unique list of IPs with port 80 open.
5 – References and Substitutions
5.1 – Numeric References
- (abc)def\1
- Create a group (abc), then refer to the group by the order in which it was created \1.
- Match: abcdefabc
- Regex: (abc)def(ghi|\1)jkl\2
- Matches: abcdefghijklghi, abcdefghijklabc, abcdefabcjklghi, abcdefghijklabc
Try it at Home – Regexercise 5.1: HTML script tags
Back to the source HTML of this page: https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
Find all instances of <script>Some text here</script>. Bonus: find all instances of <script some text here>some code here</script>
5.2 – Named Groups
- (?:abc)(?<beans>([\d]ef)(?=ghi))jkl\g<beans>
- (?:abc)(?P<green>([\d]ef)(?=ghi))jkl(?P=green)
- These do the exact same thing, there are just several different flavors of regex. There are more interpretations besides the ones listed above, so if something’s not working, Google “regex named groups <your language or technology>”. Here are some resources:
- Match: abc1efghijkl1efghi, Result: 1efjkl1ef
Try it at Home – Regexercise 5.2: HTML script tags
Back to the source HTML of this page: https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
Perform Regexercise 5.1, but this time use named groups. Your text editor may use a different regex flavor; identifying that is part of this exercise.
6 – Miscellaneous
Python Example
import rereg_head = re.compile(‘\w*(-\w*):\s.’) # header line in a requestif reg_head.match(line): #…
- Sed, Awk, Xargs – these things exist
- Different regex flavors – these too
- Excel – is beauteous
7 – Links
A note about resources
You are responsible for the safety of your information and CRITICALSTART does not control third-party sites. Be aware that sites may store your information and sanitize any input accordingly.
- https://regexr.com/
- https://www.regular-expressions.info/
- https://www.criticalstart.com/cisco-umbrella-enterprise-roaming-client-and-enterprise-roaming-module-privilege-escalation-vulnerability/
- https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
- https://nmap.org/book/output-formats-grepable-output.html
New course offered at BlackHat 2020:
To help sharpen the skills of penetration testers and threat hunting teams, TEAMARES will be offering an onsite training course at BlackHat USA 2020 in “Adversary Emulation and Active Defense.” This course will provide information security concepts utilized in both offense and defense. Attendees will learn skills that can be applied to increase capability from both sides including exploitation, circumventing defenses and lateral movement from an attacker’s perspective. The course will also cover key techniques for detection, threat hunting and mitigation to counter an attacker’s toolbox.
Follow us on Twitter @TeamAresSec and @CRITICALSTART to stay up to date
Credit:
By @DoraTexplorer17 | Adversarial Engineer, TEAMARES at CRITICALSTART

